

Claude 3.5编程收入暴增10倍,抢走Cursor反杀OpenAI!估值180亿初创3年颠覆硅谷
Claude 3.5编程收入暴增10倍,抢走Cursor反杀OpenAI!估值180亿初创3年颠覆硅谷成立仅三年,估值180亿美金Anthropic正义迅雷不及掩耳之势,一步步蚕食OpenAI市场份额。在过去3个月,他们编程收入暴增10倍,还抢走了最火的Cursor,OpenAI的高管们彻底坐不住了!
来自主题: AI资讯
8753 点击 2024-12-15 19:40
成立仅三年,估值180亿美金Anthropic正义迅雷不及掩耳之势,一步步蚕食OpenAI市场份额。在过去3个月,他们编程收入暴增10倍,还抢走了最火的Cursor,OpenAI的高管们彻底坐不住了!

全网独一份o1 pro架构爆料来了!首创自洽性机制打破推理极限,「草莓训练」系统首次揭秘。更令人震惊的是,OpenAI和Anthropic自留Orion、Claude 3.5超大杯,并不是内部失败了,而是它们成为数据生成的秘密武器。
传闻反转了,Claude 3.5 Opus没有训练失败。 只是Anthropic训练好了,暗中压住不公开。 semianalysis分析师爆料,Claude 3.5超大杯被藏起来,只用于内部数据合成以及强化学习奖励建模。 Claude 3.5 Sonnet就是如此训练而来。

围剿英伟达,数十万颗自研二代芯片超算在建!亚马逊祭出地表最强全家桶,多模态Nova击败GPT-4o。

我们需要的是「真正解放双手的智能体」。 最近一段时间,大模型领域正在经历智能体(AI Agent)引发的革命。Anthropic 推出的升级版 Claude 3.5 Sonnet,一经推出即引爆了 AI 圈。
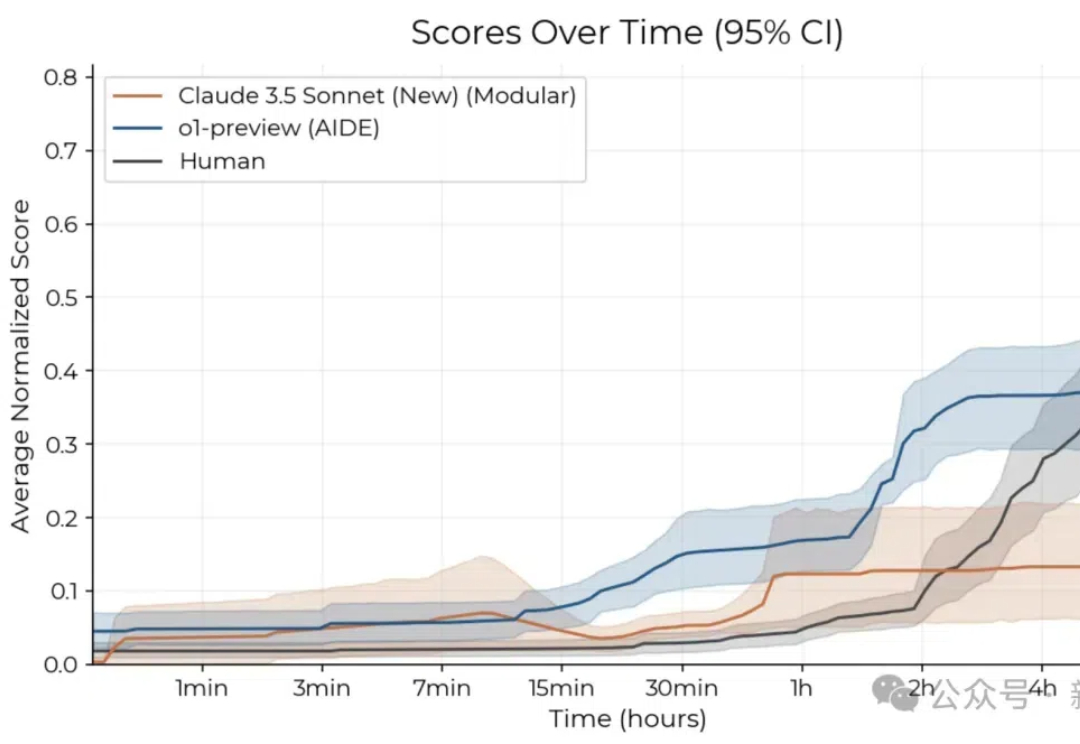
AI自主研发会真的「失控」了吗?最新研究显示,Claude 3.5 Sonnet和o1-preview在2小时内的研发任务中,击败了50多位人类专家。但另一个耐人寻味的现象是,给予更长时间周期后,人类专家在8小时任务中优势显现。
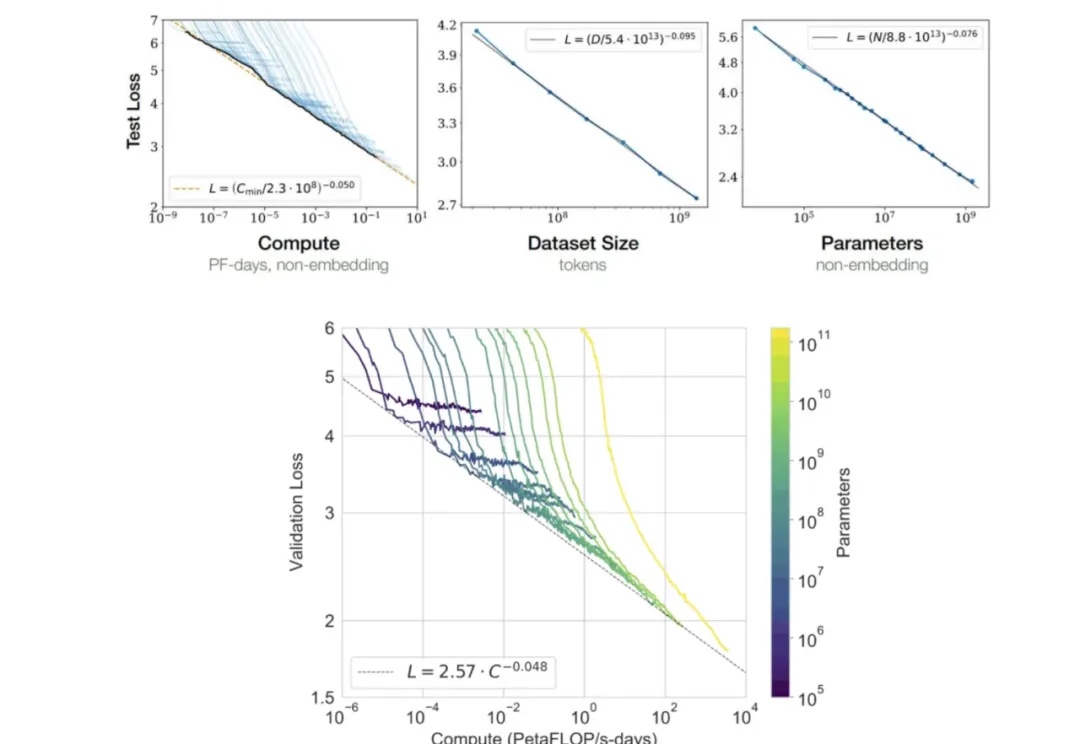
Claude 3.5 Sonnet 应该是目前公认综合能力最好的基础模型。
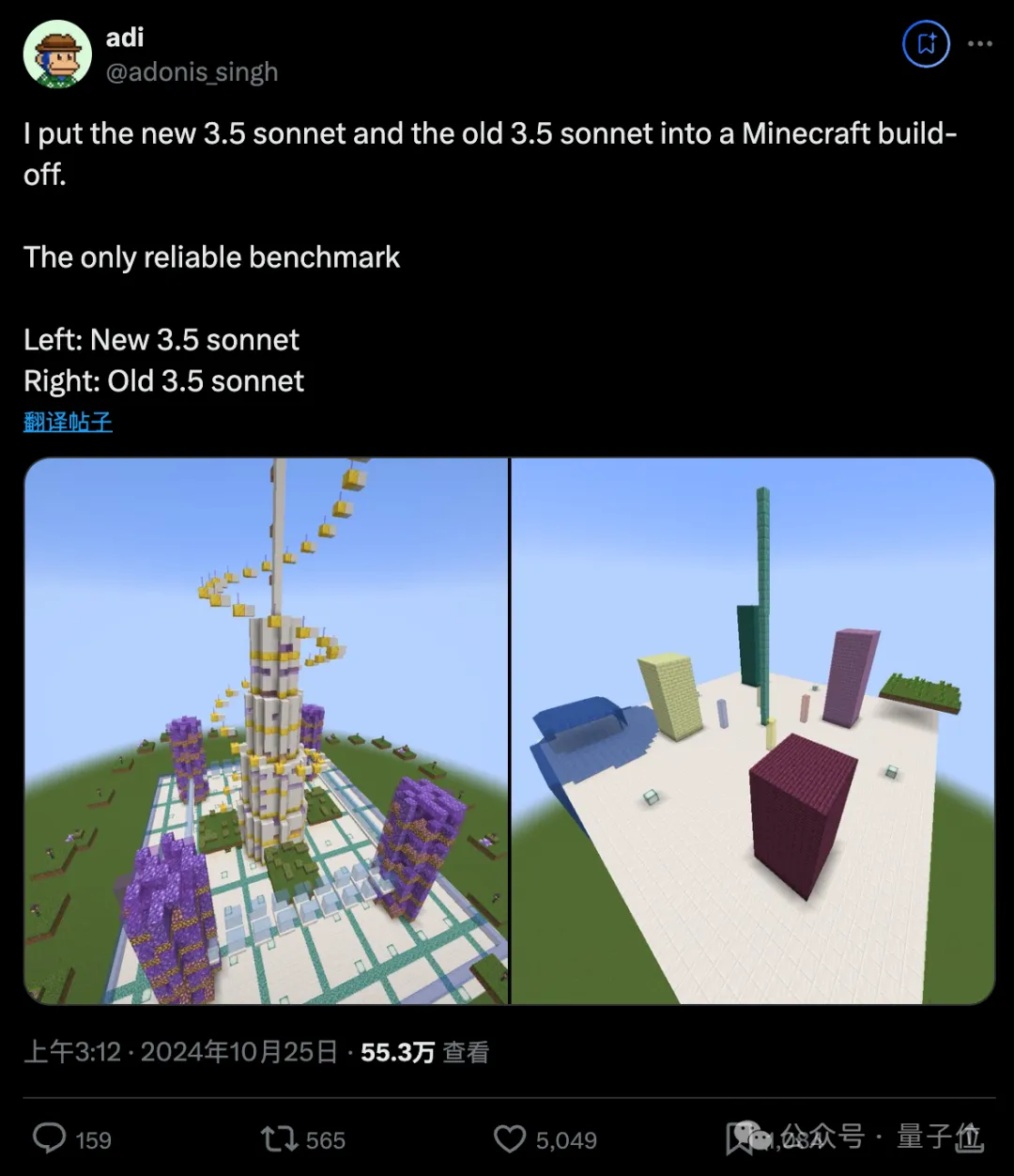
测评大模型Agent能力,从未如此直观。 新旧两版Claude 3.5 Sonnet在《我的世界》里PK盖楼,差距不要太明显,引来大量围观。

研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。

当地时间11月7日,Anthropic与Palantir Technologies Inc.和亚马逊网络服务(AWS)合作,将Claude 3和3.5系列AI模型引入AWS,服务于美国情报和国防机构。